
A Basil Plant
InfoSec Person | Alt-Account#2
- 1 Post
- 19 Comments

 6·28 days ago
6·28 days agoNo. Fuck this shit. Don’t do this.
It’s already bad when everyone in this community shoves their distro down potential linux-converts’ throats, thereby confusing them even more. Don’t tell (or imply to) freshly converted users that they potentially made a wrong choice.
TF do you think they’re going to do now? Move to fedora? The commenter above already stated that it was a hassle to install Ubuntu and now you’re telling them to change distros already???
Ubuntu is still great… compared to Windows. Sure. It may not hold to your ideals. Compared to other distros, canonical may make some questionable choices. BUT THEY DON’T IMPLEMENT A FUCKING RECALL. So it’s fine (for now).
Ubuntu is fine for newcomers. It has a shit ton of support online and you can easily search questions whose answers are likely to be found within the first few results.
So stop shoving distros down people’s throats, especially fresh users.
I know you said:
Sorry if I sound too hard… take it with a laugh 😁
It doesn’t come across that way. You come off as a gatekeeper.
Thank you, I’ll send you an email within a day.
Would you consider sending it to Austria? I’d pay shipping charges (if it’s within reason lol). If you are, you can send me an email at:
sneela-hwelemmy92fd [at] port87.com
Are you planning to scrap the CPU? I may be interested in it as I find faulty hardware fun to experiment on.
You haven’t given us much information about the CPU. That is very important when dealing with Machine Check Errors (MCEs).
I’ve done a bit of work with MCEs and AMD CPUs, so I’ll help with understanding what may be going wrong and what you probably can do.
I’ve done a bit of searching from the microcode & the Dell Wyse thin client that you mentioned. From what I can garner, are you using a Dell Wyse 5060 Thin Client with an AMD steppe Eagle GX-424 [1]? This is my assumption for the rest of this comment.
Machine Check Errors (MCEs) are hard to decipher find out without the right documentation. As far as I can tell from AMD’s Data Sheet for the G-Series [2], this CPU belongs to family 16H.
You have two MCEs in your image:
- CPU Core 0, Bank 4: f600000000070f0f
- CPU Core 1, Bank 1: b400000001020103
Now, you can attempt to decipher these with a tool I used some time ago, MCE-Ryzen-Decoder [4]; you may note that the name says Ryzen - this tool only decodes MCEs of Ryzen architectures. However, MCE designs may not change much between families, but I wouldn’t bank (pun not intended) on it because it seems that the G-Series are an embedded SOC compared to the Ryzen CPUs which are not. I gave it a shot and the tool spit out that you may have an issue in:
$ python3 run.py 04 f600000000070f0f Bank: Read-As-Zero (RAZ) Error: ( 0x7) $ python3 run.py 01 b400000001020103 Bank: Instruction Fetch Unit (IF) Error: IC Full Tag Parity Error (TagParity 0x2)Wouldn’t bank (pun intended this time) on it though.
What you can do is to go through the AMD Family 16H’s BIOS and Kernel Developer Guide [3] (Section 2.16.1.5 Error Code). From Section 2.16.1.1 Machine Check Registers, it looks like Bank 01 corresponds to the IC (Instruction Cache) and Bank 04 corresponds to the NB (Northbridge). This means that the CPU found issues in the NB in core 0 and the IC in core 1. You can go even further and check what those exact codes decipher to, but I wouldn’t put in that much effort - there’s not much you can do with that info (maybe the NB, but… too much effort). There are some MSRs that you can read out that correspond to errors of these banks (from Table 86: Registers Commonly Used for Diagnosis), but like I said, there’s not much you can do with this info anyway.
Okay, now that the boring part is over (it was fun for me), what can you do? It looks like the CPU is a quad core CPU. I take it to mean that it’s 4 cores * 2 SMT threads. If you have access to the linux command line parameters [5], say via GRUB for example, I would try to isolate the two faulty cores we see here: core 0 and core 1. Add
isolcpus=0,1to see the kernel boots. There’s a good chance that we see only two CPU cores failing, but others may also be faulty but the errors weren’t spit out. It’s worth a shot, but it may not work.Alternatively, you can tell the kernel to disable MCE checks entirely and continue executing; this can be done with the
mce=offcommand line parameter [6] . Beware that this means that you’re now willingly running code on a CPU with two cores that have been shown to be faulty (so far).isolcpuswill make sure that the kernel doesn’t execute any “user” code on those cores unless asked to (viatasksetfor example)Apart from this, like others have pointed out, the red dots on the screen aren’t a great sign. Maybe you can individually replace defective parts, or maybe you have to buy a new machine entirely. What I told you with this comment is to check whether your CPU still works with 2 SMT threads faulty.
Good luck and I hope you fix your server 🤞.
Edited to add: I have seen MCEs appear due to extremely low/high/fluctuating voltages. As others pointed out, your PSU or other components related to power could be busted.
[4] https://github.com/DimitriFourny/MCE-Ryzen-Decoder
[5] https://www.kernel.org/doc/html/latest/admin-guide/kernel-parameters.html
[6] https://elixir.bootlin.com/linux/v6.9.2/source/Documentation/arch/x86/x86_64/boot-options.rst
The debug version you compile doesn’t affect the code; it just stores more information about symbols. The whole shtick about the debugger replacing instructions with INT3 still happens.
You can validate that the code isn’t affected yourself by running objdump on two binaries, one compiled with debug symbols and one without. Otherwise if you’re lazy (like me 😄):
https://stackoverflow.com/a/8676610
And for completeness: https://gcc.gnu.org/onlinedocs/gcc-14.1.0/gcc/Debugging-Options.html

Excellent question!
Before replacing the instruction with INT 3, the debugger keeps a note of what instruction was at that point in the code. When the CPU encounters INT 3, it hands control to the debugger.
When the debugging operations are done, the debugger replaces the INT 3 with the original instruction and makes the instruction pointer go back one step, thereby ensuring that the original instruction is executed.
https://en.wikipedia.org/wiki/INT_(x86_instruction) (scroll down to INT3)
https://stackoverflow.com/a/61946177
The TL;DR is that it’s used by debuggers to set a breakpoint in code.
For example, if you’re familiar with gdb, one of the simplest ways to make code stop executing at a particular point in the code is to add a breakpoint there.
Gdb replaces the instruction at the breakpoint with 0xCC, which happens to be the opcode for INT 3 — generate interrupt 3. When the CPU encounters the instruction, it generates interrupt 3, following which the kernel’s interrupt handler sends a signal (SIGTRAP) to the debugger. Thus, the debugger will know it’s meant to start a debugging loop there.
 6·2 months ago
6·2 months agoYou can use add-ons in Firefox for Android. Not sure what version you’re running (I’m on 125.2.0) and I can use many extensions:
https://addons.mozilla.org/en-US/android/addon/ublock-origin/ should directly let you add or remove the extension.
Surprised no one’s mentioned HTTP Cats yet:
Personally, HTTP 405 (Method not allowed) is my favorite:

 3·6 months ago
3·6 months ago- Got a text-based launcher (Lunar Launcher)
By this, do you mean this launcher for Android? Searching duckduckgo predominantly leads me to a launcher with the same name for Minecraft
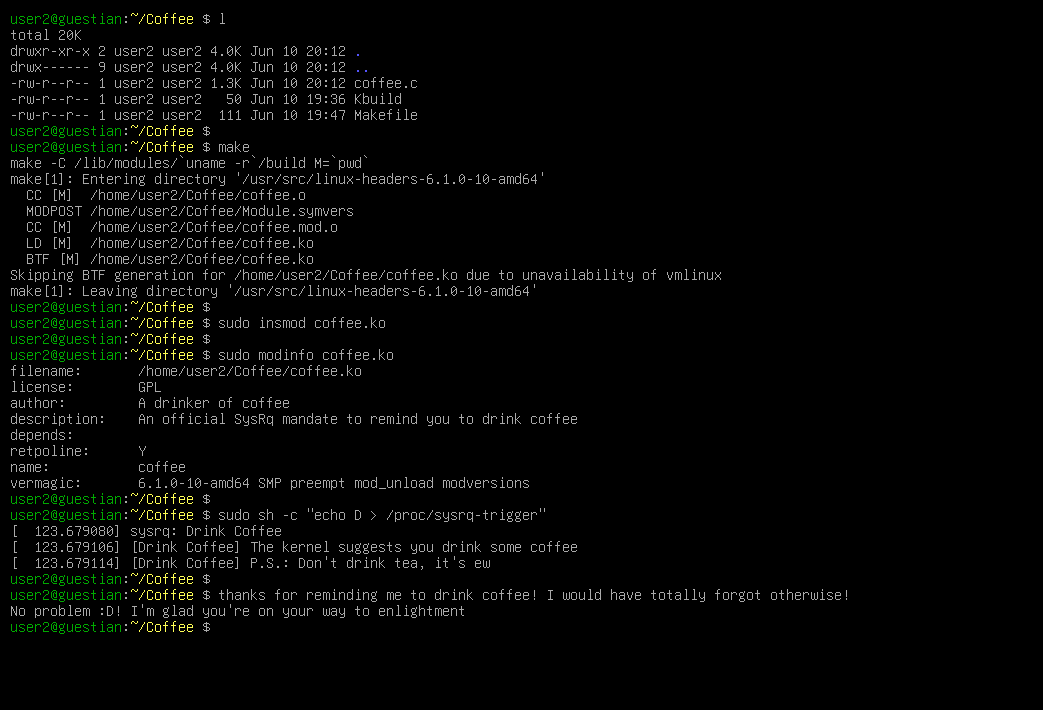
You’re right, that’s exactly what happened. If you look at the top of the trace, it says __handle_sysrq. Moreover, it’s in the
sysrq_handle_crash. That gets called when a sysrq combo is pressed.
Absolutely. Check out side channel attacks. The problem here isn’t about software exploits, but hardware issues. https://en.wikipedia.org/wiki/Side-channel_attack
Some things to get you started: Meltdown and Spectre: https://en.wikipedia.org/wiki/Meltdown_(security_vulnerability), https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)
Rowhammer: https://en.wikipedia.org/wiki/Row_hammer
These are exploited by malicious processes doing something to the hardware which may result in information about your process(es) being leaked. Now, if this is on your computer, then the chances of encountering a malicious process that exploits this hardware bug would be low.
However, when you move this scenario to the cloud, things become more possible. Your vm/container is being scheduled on CPUs that may/may not be shared by other containers. All it would take is for a malicious guest VM to be scheduled on the same core/CPU as you and try exploiting the same hardware you’re sharing.
 4·7 months ago
4·7 months agoI’ve been using Hugo since 2017. I recommend it wholeheartedly.
That title is… something
You need to have end cards enabled.
I’m glad you appreciate it! It’s always fun digging into kernel internals and learning new things :D
I’m also open to criticism about the writing if you have any.