Atemu
Interested in Linux, FOSS, data storage systems, unfucking our society and a bit of gaming.
I help maintain Nixpkgs.
https://github.com/Atemu
https://reddit.com/u/Atemu12 (Probably won’t be active much anymore.)
- 19 Posts
- 494 Comments




Right from the horse’s mouth ;)
https://mastodon.social/users/protonprivacy/statuses/112162248226735964
more and more customary that (for some reason) they want your photo
Gotta keep the people with different skin colour out
What does this have to do with privacy? It’s just a userscript to modify the regular Twitter website with all its human rights abuse.
Realtek LAN is usually not too bad.
For WiFi, you want mediatek or Intel though.
They’re in the middle of a rollout of a rewrite and have promised to publish the source soon.
While I wouldn’t put it past tech bros to use such unethical measures for their latest grift, it’s not a given that it’s actually
claudebot. Anyone can claim to beclaudebot,googlebot,boredsquirrelbotor anything else. In fact it could very well be a competitor aiming to harm Claude’s reputation.
Usually, fundamental rights cannot be “sold”
It’s really quite perverse if you think about it.

Thank you for your thoughts, I really enjoyed reading them :)

Not that I can tell; just an explanation how df works on Linux and macOS.
parents are a motor to innovation
Absolutely. No parents -> No children -> No innovation.

Why is this being downvoted? It’s clearly labelled as Japanese; if you don’t want to see foreign languages, filter them out.
I used to not but I wish I did. I want to know where pictures were taken. Photo album software like Immich can also make cool maps out of your photos this way and group photos by location.
As long as you’re not sharing the pictures with anyone, there is no loss of privacy whatsoever in doing this. I don’t see any reason to generally label it as “not great for privacy”.
When sharing publicly, you need to be careful of course and run the images through an EXIF metadata stripper.

 1·3 months ago
1·3 months agoYou activated my trap card!
It’s entierly based on the excellent org-mode for Emacs.
I am not. Read the context mate.

They were mentioned because a file they are the code owner of was modified in the PR.
The modifications came from another branch which you accidentally(?) merged into yours. The problem is that those commits weren’t in master yet, so GH considers them to be part of the changeset of your branch. If they were in master already, GH would only consider the merge commit itself part of the change set and it does not contain any changes itself (unless you resolved a conflict).
If you had rebased atop of the other branch, you would have still had the commits of the other branch in your changeset; it’d be as if you tried to merge the other branch into master + your changes.
The thing is, you can get your cake and eat it too. Rebase your feature branches while in development and then merge them to the main branch when they’re done.
Note that I didn’t say that you should never squash commits. You should do that but with the intention of producing a clearer history, not as a general rule eliminating any possibly useful history.
 1·3 months ago
1·3 months agoYour search results look very different to mine:
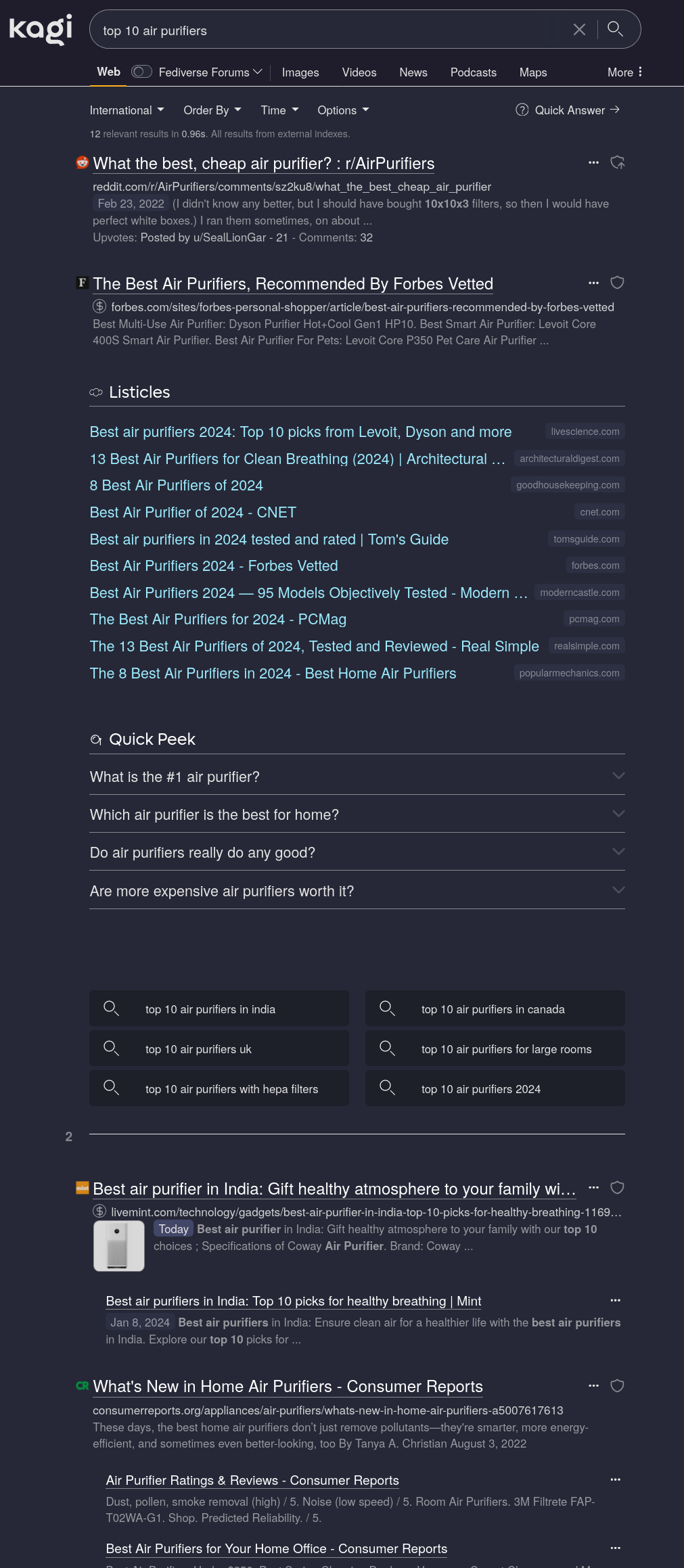
Did you disable Grouped Results?
All the LLM-generated “top 10” listicles are grouped into one large block I can safely ignore. (I could hide them entirely but the visual grouping allows for easy mental filtering, so I haven’t bothered.) Your weird top10 fake site does not show up.
But yes, as the linked article says, Kagi is primarily a proxy for Google with some extra on top. This is, unfortunately, a feature as Google’s index still reigns supreme for general purpose search. It absolutely is bad and getting worse but sadly still the best you can get. Using only non-Google indices would just result in bad search results.
The Google-ness is somewhat mitigated by Kagi-exclusive features such as the LLM garbage grouping.What Google also cannot do is highlighted in my screenshot: You can customise filtering and ranking.
The first search result is a Reddit thread with some decent discussion because I configured Kagi to prefer Reddit search results. In the case of household appliances, this doesn’t do a whole lot as I have not researched trusted/untrusted sources in this field yet but it’s very noticeable in fields like programming where I have manually ranked sites.Kagi is not “all about” privacy. It’s a factor, sure but ultimately you still have to trust a U.S. company. Better than “trusting” a known abuser (Google, M$) but without an external audit, I wouldn’t put too much wight into this.
The index ain’t it either as it’s mostly Google though sometimes a bit better.
What really sets it apart is the features. Customised ranking aswell as blocking some sites outright (bye bye pinterest and userbenchmark) are immensely useful. So are filtering garbage results that Google still likes to return.










Steam is its own package manager and native games usually assume that an FHS-conformant is present. Neither of those mesh well with Nix notoriously has nothing comparable to an FHS and usually requires everything to be defined in its terms.