

You make an excellent point. I have a lot more patience for something I can understand, control, and most importantly, modify to my needs. Compared to an iThing (when it’s interacting with other iThings anyway) Linux is typically embarrassingly user hostile.
If course, if you want your iThing to do something Apple hasn’t decided you should want to do, it’s a Total Fucking Nightmare to get working, so you use the OS that supports your priorities.
Still, I really appreciate the Free software that goes out of its way to make things easy, and it’s something I prioritise in my own Free software offerings.


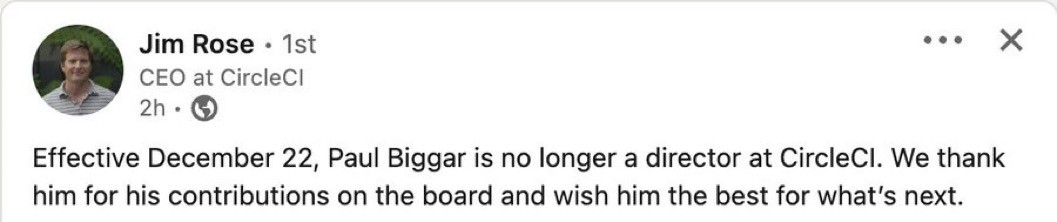
This too is an excellent take. “Artificial pain points” for capitalism, or “learn some shit” for Linux. Love it.